En este caso vamos a hacer una pequeña introducción al clustering con Weka.
Los algoritmos de clustering permiten clasificar un conjunto de elementos de muestra en un determinado número de grupos basándose en las semejanzas y diferencias existentes entre los componentes de la muestra.
Para esta pequeña introducción vamos a tratar de separar las 52 provincias españolas en clusters basándonos en algunas de sus características sociodemográficas.
Partiremos del fichero provincias.arff que contiene una serie de datos para cada una de las 52 provincias. Los datos son:
- Nombre de la provincia
- Población
- Ratio varones/mujeres
- Ratio extranjeros/españoles
- Extensión de la provincia (en Km2)
- Paro
- Número de teléfonos fijos registrados
- Número de vehículos de motor matriculados
- Número de oficinas bancarias
- Precio medio del m2 de vivienda
Todos los datos que contiene el fichero ARFF son reales y han sido extraídos del anuario económico de La Caixa del año 2006 y de la página web del Ministerio de Vivienda.
Para empezar abrimos la ventana Explorer de Weka y desde la pestaña Preprocess abrimos el fichero provincias.arff que comentábamos antes.
Ahora que ya hemos cargado los datos nos vamos directamente a la pestaña Cluster, pinchamos en Choose y escogemos SimpleKMeans como algoritmo de clustering.
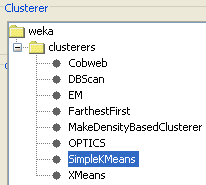
A continuación pinchamos sobre el nombre del algoritmo para configurar sus propiedades. En este ejemplo vamos a querer obtener 3 clusters de provincias, así que configuramos el atributo numClusters con valor 3 y pulsamos en OK.
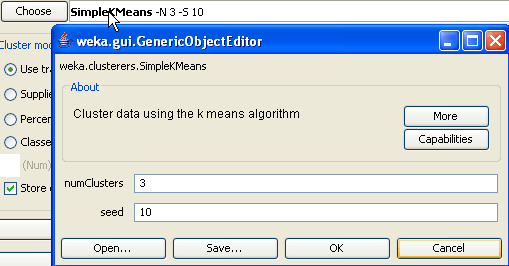
Antes de ejecutar nuestro primer clustering tenemos que seleccionar los atributos que NO queremos usar en el proceso de entre los que contiene el fichero ARFF inicial de datos. Por ejemplo, no tiene sentido utilizar el nombre de la provincia ya que no aporta ninguna información útil para la separación en clusters de las provincias.
En el ejemplo vamos a quedarnos con las siguientes columnas de datos: población, ratio de extranjeros/españoles, paro y precio medio del m2 de vivienda. Para ello pinchamos en Ignore attributes y seleccionamos los demás atributos.
Ahora ya sí que estamos preparados para ejecutar el clustering así que pinchamos en Start y en un momento estaremos viendo los resultados.
De momento vamos a fijarnos en la siguiente sección que aparece al final del documento que Weka ha generado:
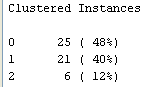
Como véis, hemos conseguido 3 clusters con 25, 21 y 6 provincias respectivamente. Podemos ver la distribución de una manera más gráfica pinchando con el botón derecho sobre la entrada correspondiente del listado de la derecha y después en Visualize cluster assignments.
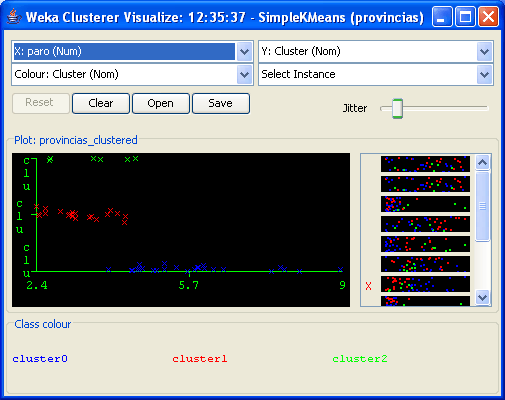
Desde esta pantalla podemos generar múltiples gráficas eligiendo cualquier combinación de atributos para los ejes.
Una vez obtenidos los clusters probablemente necesitemos guardar los resultados para procesarlos o utilizarlos posteriormente. Esto se hace desde la ventana de visualización anterior (la de las gráficas) pinchando sobre el botón Save.
Desde aquí podemos generar otro fichero ARFF que simplemente añade una columna con el cluster al fichero inicial de datos.
Guardaremos los resultados para experimentar un poco con ellos y para utilizarlos en el próximo artículo para investigar nuevas funcionalidades de Weka.